Logos Research has recently started working with a small and very exclusive set of top universities and quant funds. They are a new entrant among mathematical reasoning companies, joining startups such as Axiom, Harmonic, Math.Inc and Logical Intelligence.
Logos stands out for being built by a mixture of world-class mathematicians and quant finance managers, a combination reminiscent of Renaissance Technologies (Jim Simons’ legendary quant fund). Prof. Cris Salvi, the CEO, is Associate Professor of Mathametics and Machine Learning at Imperial College London. Robert Smith, the CTO, was former Global Head of Automated Trading and Data Science at Citi. Heavyweights such as leading expert in formal mathematics Prof. Kevin Buzzard, Fields Medalist, Prof. Martin Hairer, and Oxford Wallis Professor of Mathematics, Prof. Massimiliano Gubinelli, are just some among several others top mathematicians and financial engineers who joined Logos as scientific collaborators.
Logos has been operating in stealth, but recently opened early access to LogosLib, an infrastructure layer designed to let AI agents reason mathematically over long horizons without hallucinating.
So we sat down with CEO Prof. Cris Salvi to discuss Logos and how formal mathematical verification can eliminate hallucinations from AI-generated code, and why that matters for industries from quantitative finance to mission-critical software.
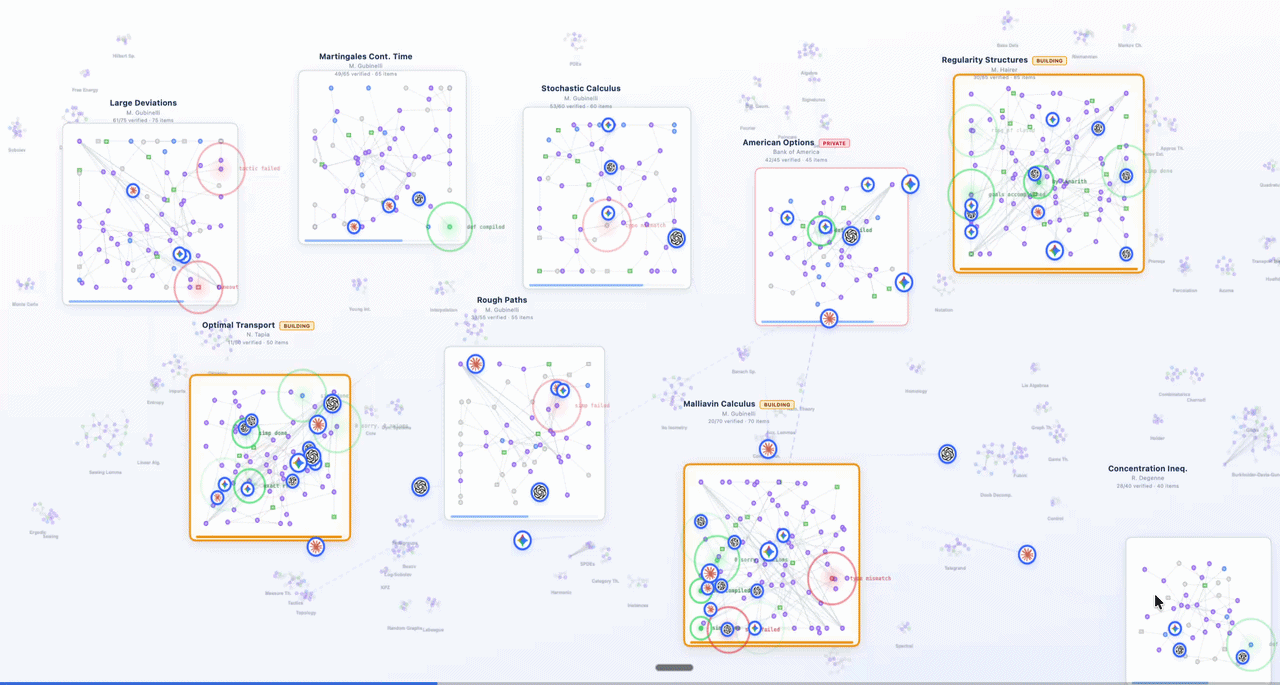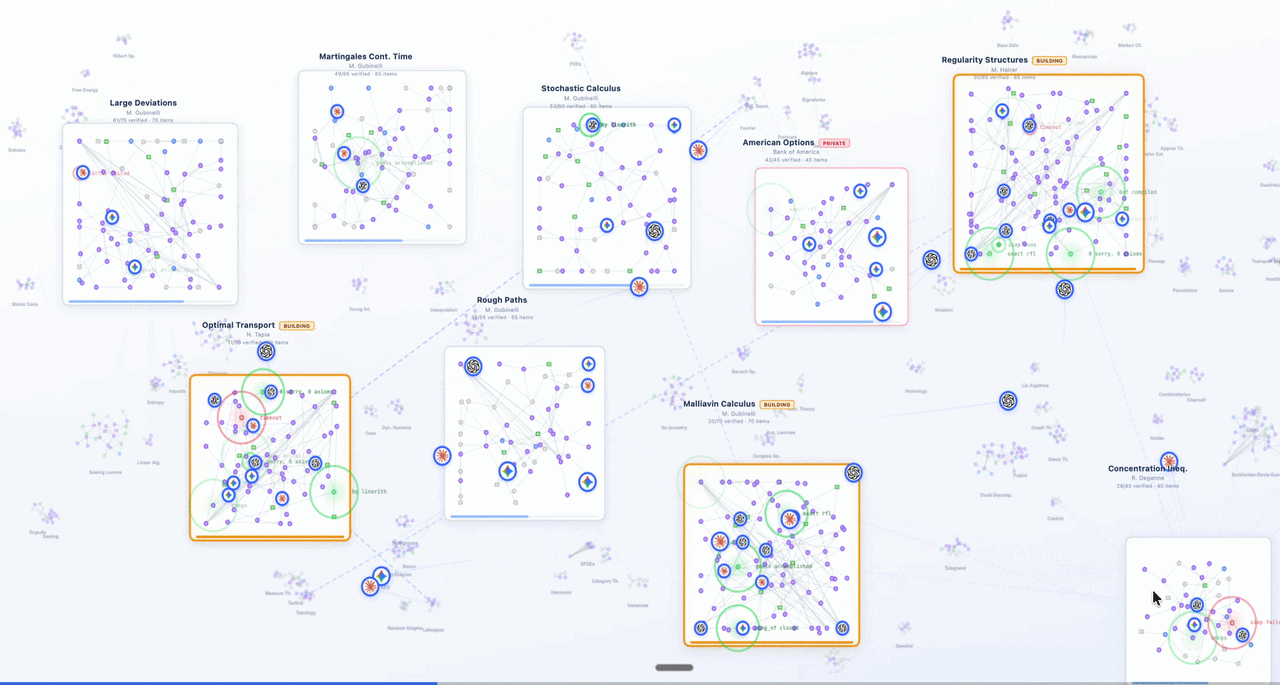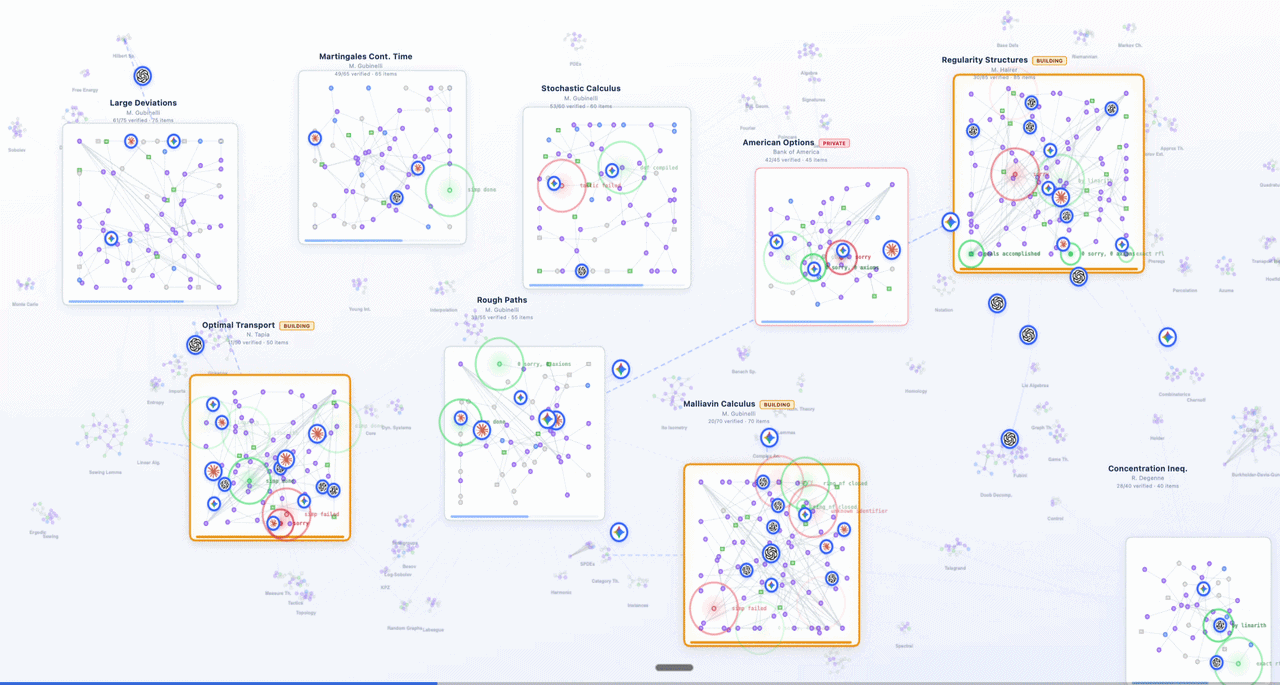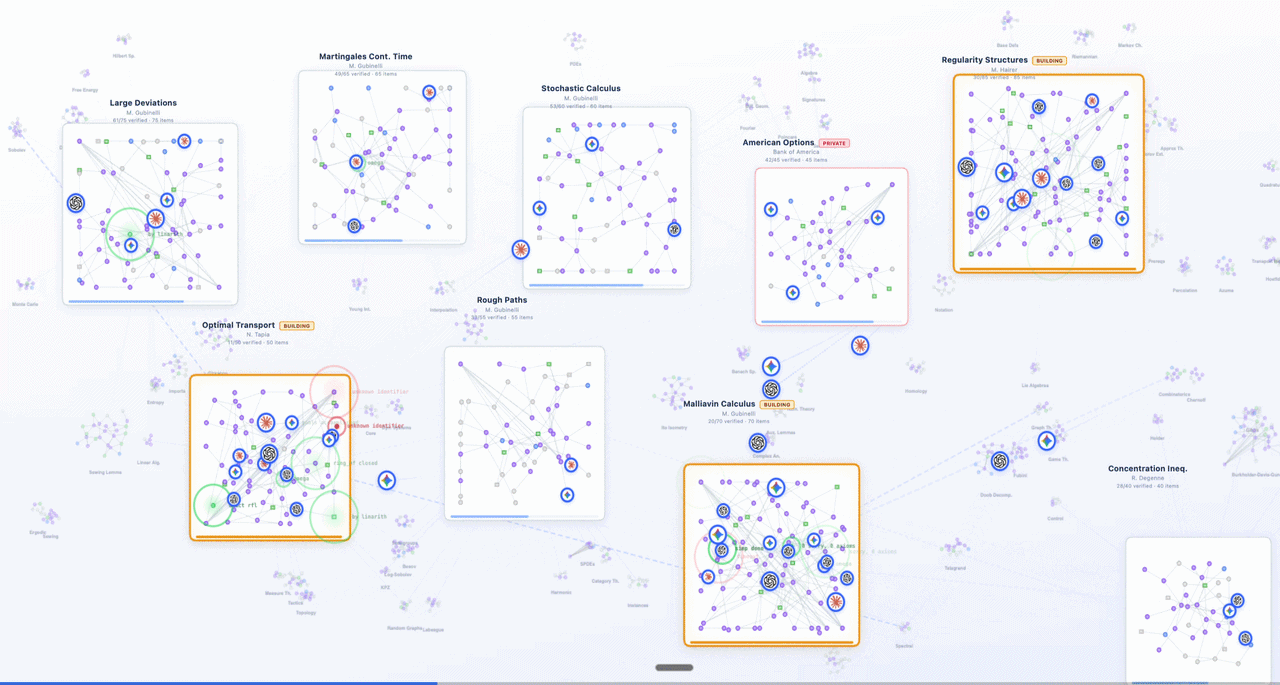
Logos MCP in action: model-agnostic agents with Logos-powered verified chain-of-thought,
indexed on LogosLib, being function-called for financial, regulatory, and mathematical verification.
Po Bronson: The media has covered many stories about the problems with AI generated code – everything from low end vibe coding resulting in glitchy social media to mission critical servers at big tech firms taken down by faulty software updates. But are there any actual industry statistics about how prevalent the problem really is?
Cris Salvi: Yes, you have recent published statistics on hundreds of GitHub PRs that say that AI-generated code has on average almost twice as many bugs as human code. Numbers get much worse on long horizon tasks.
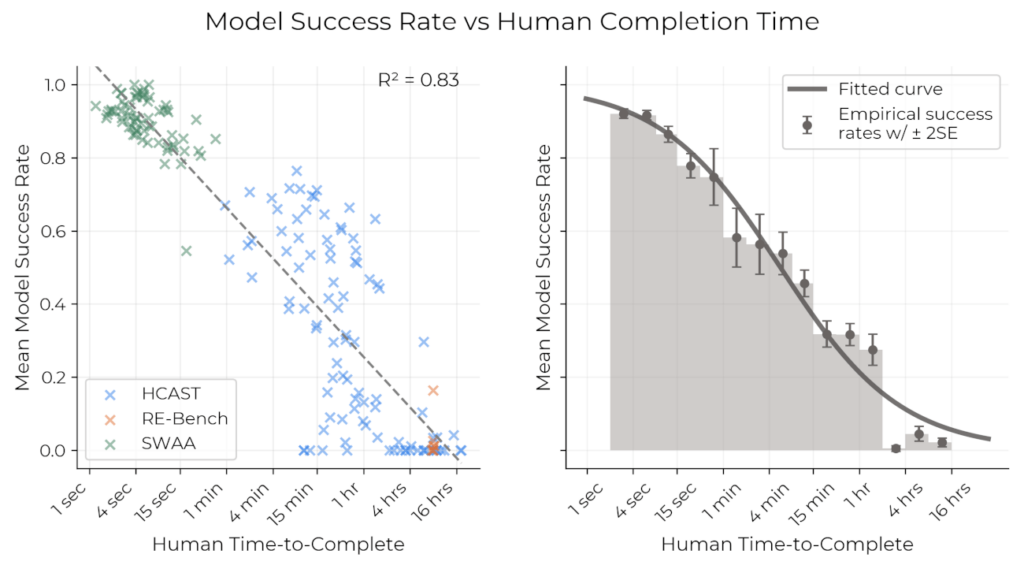
Parikshit Sharma: METR showed that if it’s something simple a human coder could do in, say, just 4 minutes, then AI code is fine and will work nearly 100% of the time. But if it’s much more substantial work, let’s say the kind of work a human coder would complete in 4 hours, AI code works only about 10% of the time.
Po Bronson: The conventional wisdom is that programmers run the AI generated code back through scaffolding agents to test and fix the code.
Cris Salvi: There are published leaderboards tracking how well models do at finding and fixing bugs. Even the top models still fail when bugs are about logical flaws in the code, the kind of thing that a debugger or a suite of unit tests escape.
Po Bronson: So how do programmers then feel about AI generated code?
Cris Salvi: Because the more complex the task, the more likely the model is to hallucinate, coding agents haven’t made it yet in technical fields like quant finance. In these domains a logic error can mean a failed proof, a crashed system, or millions lost on a bad trade. So, there is essentially a lack of trust because of hallucinations.
Po Bronson: Most people might assume, “Well, it’ll get better fast.” Two years ago, the LLMs hallucinated on basic research textual questions, but today they are incredible. I need you to slowly explain to the audience why this doesn’t just resolve itself with time and practice and reinforcement.
Cris Salvi: Coding agents generate code with a certain level of randomness. Classical compilers catch syntax errors. Unit tests catch some logic errors, the ones you’ve seen before and thought about writing tests for. But the problems are edge cases you haven’t observed in historical data or haven’t thought about, like a crash, a cyber-attack, an earthquake. Unit tests can’t cover what you can’t anticipate.
Po Bronson: Say more. Give me some context what that’s like day to day, not just in rare events, catastrophic as they might be.
Cris Salvi: Take a quant team in a hedge fund tasked with predicting future market returns. They would usually split historical time series into train, validation, test sets over rolling windows. Then, they would run complex pipelines to extract financial features over each window and train regression models to predict probabilistic quantity over future windows. A common problem is that somewhere in the feature pipeline, a quantity computed at a given time depends on data from future times, for example due to a normalisation done over the full dataset before the split. This “lookahead information leakage” is hard to detect because it is not a classical coding bug, it’s a logical bug. Back-tests run end to end and look excellent, but when the strategy is deployed live, the features the model receives are different, and the strategy overfits and underperforms.
Po Bronson: Okay and back to catastrophes – are there famous examples of poor code causing huge losses?
Parikshit Sharma: Oh for sure. The Knight Capital meltdown was caused by one of the 8 servers not getting upgraded. An old algorithm got activated and made 4 million trades. Or there’s examples where algorithms respond to what other algorithms are doing – the Flash Crash of 2010 vaporized $1 trillion. Infinium turned on an algorithm just for five seconds before they got to the kill switch – it made 3,000 trades per second, spiking oil futures.
Po Bronson: Can you explain the different methods used to address this problem and explain what formal verification is?
Cris Salvi: There’s a spectrum. On the one hand, you have testing, run the code, see if it breaks. But unit-testing is empirical. You’re sampling from a very large, often infinite-dimensional space of possible inputs. You can almost never test them all. On the other hand, you have formal verification. Instead of testing individual cases, you write a mathematical proof that the code satisfies its specification for all possible inputs. If it compiles the logic is correct, if it doesn’t that’s a logical bug.
Po Bronson: So all of this has been the case for decades, right? How exactly is AI making this worse? Is there something inherent to the use of AI that results in logic errors?
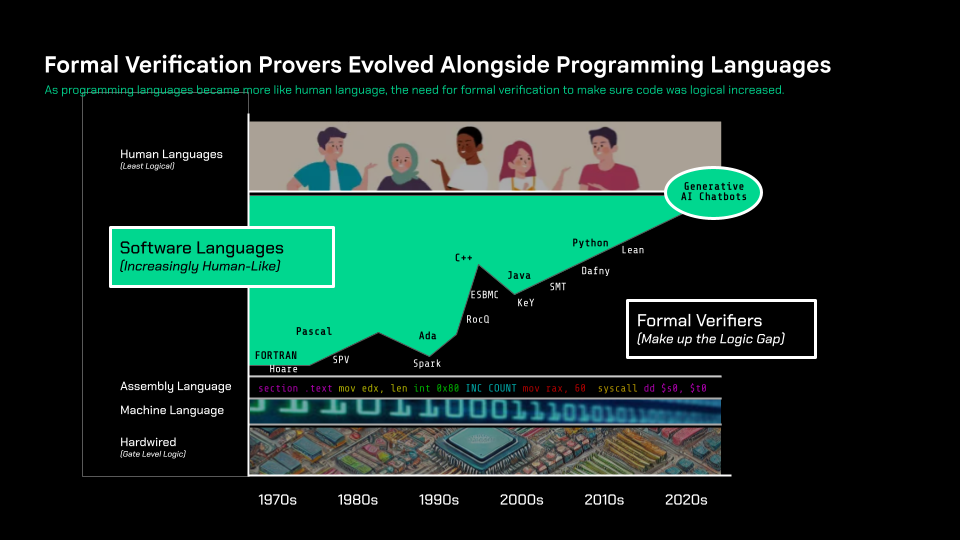
Parikshit Sharma: Yes, absolutely. Let’s take a historical perspective. Early programming languages were extremely logical and formal, but very inaccessible. As the languages became gradually more accessible, and a little more like human language, easier to use, the tradeoff was less formal precision — so it resulted in more implementation errors – stack and buffer overflows, null points, race conditions, deadlocks, floating point errors, and the like.
We’re all familiar with the evolution of programming languages – Fortran, Pascal, Ada, C++, Java, and today’s Python, et cetera. Alongside those came these companion verification languages and proof assistants, far less well known, that allowed coders to write logic proofs to check their code. If the programming language wasn’t entirely logical, the verifier language could be used to catch logic errors. Pascal was quite logical and concise, but it soon had the first real companion verifier. Languages like Ada – used by the Dept of Defense – were very logical and had guardrails. While C++ was very loose, and almost impossible to verify, so it fell out of favor. Today so much is written in Python. It’s extremely accessible, but loose, and the most popular verifier is called Lean, or Lean4.
And then, since 2022, all of sudden, anyone can spit out code just by typing into a chatbot in human language, describing what you want. Looseness and imprecision — as Cris said, randomness — is inherently the tradeoff. The need for a verifier for this new era is greater than ever.
Po Bronson: And what percent of the world’s programmers use, or what percent of the world’s code goes through this rigorous formal verification? Roughly?
Cris Salvi: Companies like AWS and Intel already use formal verification for their most critical infrastructure. But writing a formal proof is extremely complex and technical, the learning curve is brutal. So, adoption has been limited to a handful of extreme cases.
Parikshit Sharma: Industry estimates suggest that less than 1% of developers actively use formal verification methods like Lean4. For every one line of code, you might have to write 6 to 60 lines of Set Theory equations in Lean. So it’s really hard. There are 47 million software developers worldwide. Lean4 has only 11,000 regular users.
Po Bronson: Wow, that’s small. There’s a solution – but its a very big friction.
Cris Salvi: At Logos we are merging two technologies: LLMs and formal verification. We are building verified coding agents that generate bug-free code guaranteed to be correct. Essentially, a verification layer for AI.
Parikshit Sharma: Once we have autoformalization, then all code can level up and be mission-critical grade.
Po Bronson: Can we complete the thought: let’s go back to why LLMs won’t just solve this with time – are you saying that they can get better at debugging, but can’t make the jump to proving code, because they rely inherently on probabilistic inference, rather than logical deduction?
Cris Salvi: Humans write their intentions as precise specifications, LLMs randomly generate proofs, and the verification backend only retains those that compile. These three elements coexist, they have distinct and complementary roles.
Po Bronson: Do you have any benchmarks of Logos performance versus the other tools being used? I know it’s in the hands of only a handful of partners.
Cris Salvi: Yes, this solution sector benchmarks on Verina. Verina stands for Verifiable Code Generation Arena. It was released just recently by Meta and UC Berkeley. It’s a series of 189 curated coding tasks, with 108 of them more basic and 81 very complex. And there are two modalities of it. The first modality is, “here’s a reference algorithm, write a theorem that proves the algorithm works.” In the second modality, it’s harder — the problem presents a specification, “Go synthesize an algorithm and then also write a proof it works.”
Po Bronson: And how do other tools score?
Cris Salvi: On the first modality, generating a theorem for a given algorithm — for example, OpenAI’s o3 could only get 4.3% of those right. That’s illustrative that LLMs can’t do this, they’re not designed to do this. Another tool got 11.2%. But one of our “math AI” competitors, Harmonic’s Aristotle, got 96.8%.
Po Bronson: That sounds promising.
Cris Salvi: Yes, but it was on the first modality only, when the algorithm already exists and works. It could not synthesize an algorithm from a specification. Not at all. In that task, OpenAI’s o3 did better, synthesizing an algorithm 3.2% of the time.
Po Bronson: And how did Logos fare?
Cris Salvi: We got 188 of 189 correct. 99.4%. On both modalities.
Po Bronson: This is without any human intervention?
Cris Salvi: Correct.
Po Bronson: Haha. Okay, nice. You got one wrong. Left yourself room for improvement.
Cris Salvi: No, not really. We got it right. See, Verina looks up lemmas in MathLib. But we used a lemma not yet in MathLib, it’s only in LogosLib. So Verina didn’t know how to check it.
Po Bronson: You weren’t wrong, the test was wrong.
Cris Salvi: The answer checker was uninformed.
Po Bronson: You’ll need to give them access to LogosLib. And tell them to create a new battery of harder tasks.
Cris Salvi: Good idea.

Po Bronson: How does this integrate with the LLMs which are helping write AI code?
Parikshit Sharma: We are not building our own model, like Harmonic. We work with your LLM account. Logos is connected into the LLMs through their MCP server and A2A (agent 2 agent) infrastructure layer. When a code writing task, or open-ended research task is of the complexity where it needs formal verification, the LLM just calls to Logos.
Po Bronson: Okay I want to switch the train of thought for a moment. Let’s bring in the mathematicians.
Parikshit Sharma: So, Lean wasn’t invented by coders. It was actually invented by mathematicians, who used it to write formal proofs for their mathematical theorems. It worked better than any verifier that coders used, so the programming community also adopted it.
Po Bronson: Tell me about MathLib.
Cris Salvi: Mathlib is the largest open-source library of formalised mathematics in Lean. It has almost 200,000 theorems across pure mathematics. It’s an extraordinary achievement. It took the community ten years to build.
Po Bronson: And Logos is taking that to another level.
Cris Salvi: Mathlib has also real limitations. First, it covers almost exclusively pure mathematics. Large areas of applied mathematics like probability, PDEs, numerical analysis, optimisation, and statistics are essentially absent. Second, it’s governed by a small group that decides what gets accepted, Bourbaki-style.
Parikshit Sharma: So it’s scalability is very human constrained.
Cris Salvi: MathLib was built by humans, for humans. It’s a file-based library, not a database. It is not designed to be consumed or extended by LLMs. In fact, as far as I know, right now PRs with AI-generated code are just blocked. In a world where AI agents need to reason mathematically about the physical world, I think the underlying mathematical infrastructure has to be designed for them.
Po Bronson: And so what is Logos building? What’s LogosLib?
Cris Salvi: LogosLib is two things. First, a graphical database of mathematics optimised for AI. Second, an interface for AI to access it efficiently. We absorb both human and AI generated code with minimal filtering, and we have a heavy proprietary postprocessing system that keeps the library stable and usable. We’re focused on growing it in areas like probability, PDEs, numerical analysis, and we include not only general theorems but examples, counterexamples, algorithms etc. On top of this infrastructure, we’re building our own agents optimised to use it. Before we open it up to third-party agents, we’ll have a significant advantage.
Po Bronson: Help me understand what this means for quants and hedge funds. You gave an example earlier. Maybe you can go back to that, and explain how it’d be different with Logos.
Cris Salvi: Quant finance is our first vertical. It is an area where we have domain expertise, which gives us a clear edge. FinanceLib, the portion of LogosLib dedicated to quant finance, serves as a verification layer for building AI agents that reason mathematically and reliably about algo trading, portfolio optimisation, hedging, and risk management.
Po Bronson: What keeps a quant up at night?
Cris Salvi: Well, bonuses are proportional to how much money the trading strategies generate! A bug like the lookahead leakage I mentioned above can cause big losses. Detecting those bugs, or automatically generating strategies that provably don’t have them, would be transformative.
Parikshit Sharma: What’s the hardest part of a quant’s job?
Cris Salvi: There are essentially two aspects. First, predicting the future distribution of the market. Second, designing trading strategies and portfolios that make money given those predictions, subject to all sorts of constraints, risk constraints among them.
Po Bronson: And how do you help that?
Cris Salvi: A quant provides Logos with a description of their intent. We first help them refine it into a mathematically precise specification. Then, we let Logos agents process this specification; by interacting with LogosLib and the verification layer, they synthesise an algorithm together with a formal proof guaranteeing that the latter satisfies the quant’s original intention.
Parikshit Sharma: Something to point out here is how important a strong library is. Enriching these libraries with metadata, workflows, strategies, and mathematical tactics will create real network effects and make superintelligence deployable. Also, how you’ve set up LogosLib and your MCP/infrastructure, the libraries become self-growing, adding new domains quickly, with every entry machine-checked.
Cris Salvi: The design of LogosLib is key. The core challenge is designing an optimised mathematical API: how formalised mathematics should be decomposed, indexed, and structured so that AI systems can reliably retrieve and recombine it. This is mainly a data and infrastructure problem, more than a model problem.
Po Bronson: I need to ask you about a competitor, Axiom. A lot of what you are describing today does sound very similar to descriptions of Axiom. Would you agree that you’re similar? And if so, how is Logos different from Axiom?
Cris Salvi: Axiom have assembled a great AI team. But if you actually go to their website, they’re building proof verification tooling for pure mathematics. “Check any mathematical proof, instantly.” That’s their pitch. Similarly, Harmonic are building a new model to prove theorems and solve math olympiad problems. This is cool research, but it doesn’t help you if you’re a quant and you need to design a hedging strategy or rebalance a portfolio.










